I built a machine that turns AI papers into interactive explainers
LLM paper summaries are shallow and subtly wrong about the parts that matter. I wanted the opposite, so I built a pipeline that makes them, and pointed it at twenty papers.
Machine learning papers are dense on purpose: each spends its pages on one new idea and assumes you can fill in the prerequisites, so you read with a dozen tabs open.
The 2026 move is to paste the PDF into a chatbot and ask for a summary. I do it all the time, and it keeps failing me. The prose gets the shape right, but when a detail matters (which way a sign goes, exact or approximate, what variable is updated) it goes confidently wrong and you can’t tell. I wanted what a good teacher gives you: intuition first, then the math in plain language, every claim checked against the source.
The one I made by iterating
A couple of weeks ago I built one with Claude, iterating over about a week: a full explainer of the DiffusionBlocks paper. Getting the math right meant going back to the original sources, and that turned up a sign error in the paper’s own equations, the kind of thing a summary would reproduce and I’d believe. So I wondered whether I could build a machine that does the week of work: read the sources, verify the claims, design the figures, write it the way a person would, then check the draft.
intuitivepapers.ai
I put that machine live at intuitivepapers.ai. There are twenty explainers up, and a new one goes up most days.
Deep, interactive explainers, intuition first, every claim checked against the source.
The catalogue covers Attention, BERT, GANs, VAEs, CLIP, PPO, Mamba, Adam, and more. 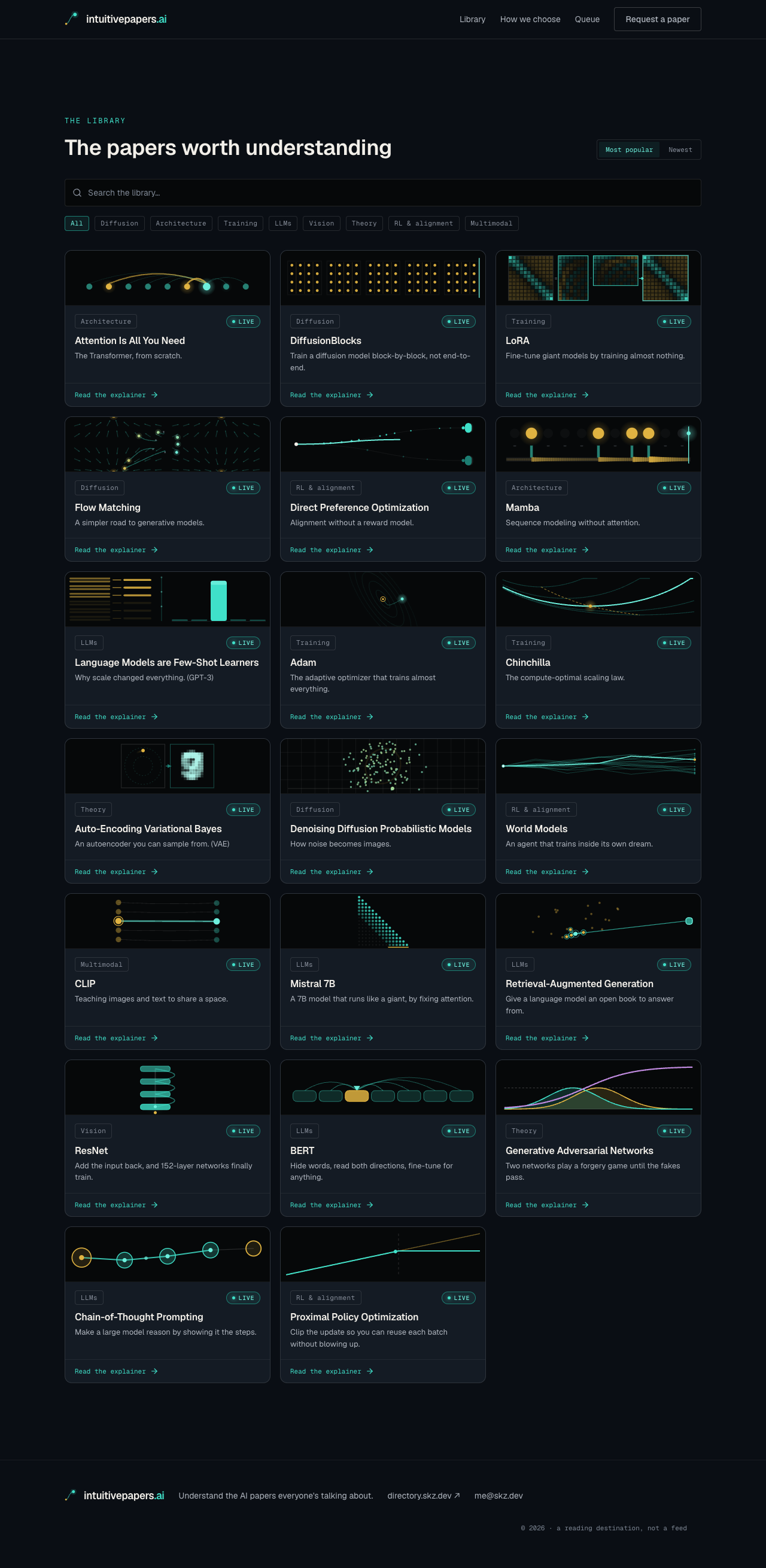
Twenty papers, each card a live preview of the signature figure from the explainer behind it.
Reading one
Each one reads as a long essay with the math built up in order. A concept tower down the side lists the prerequisites in dependency order, so you get the foundations before the new idea. Where an idea is clearer in code than in symbols, it shows a few real lines of the implementation. The figures sit in the prose: you don’t read that PPO clips the policy ratio, you drag the ratio and watch the gradient go to zero outside the trust band.
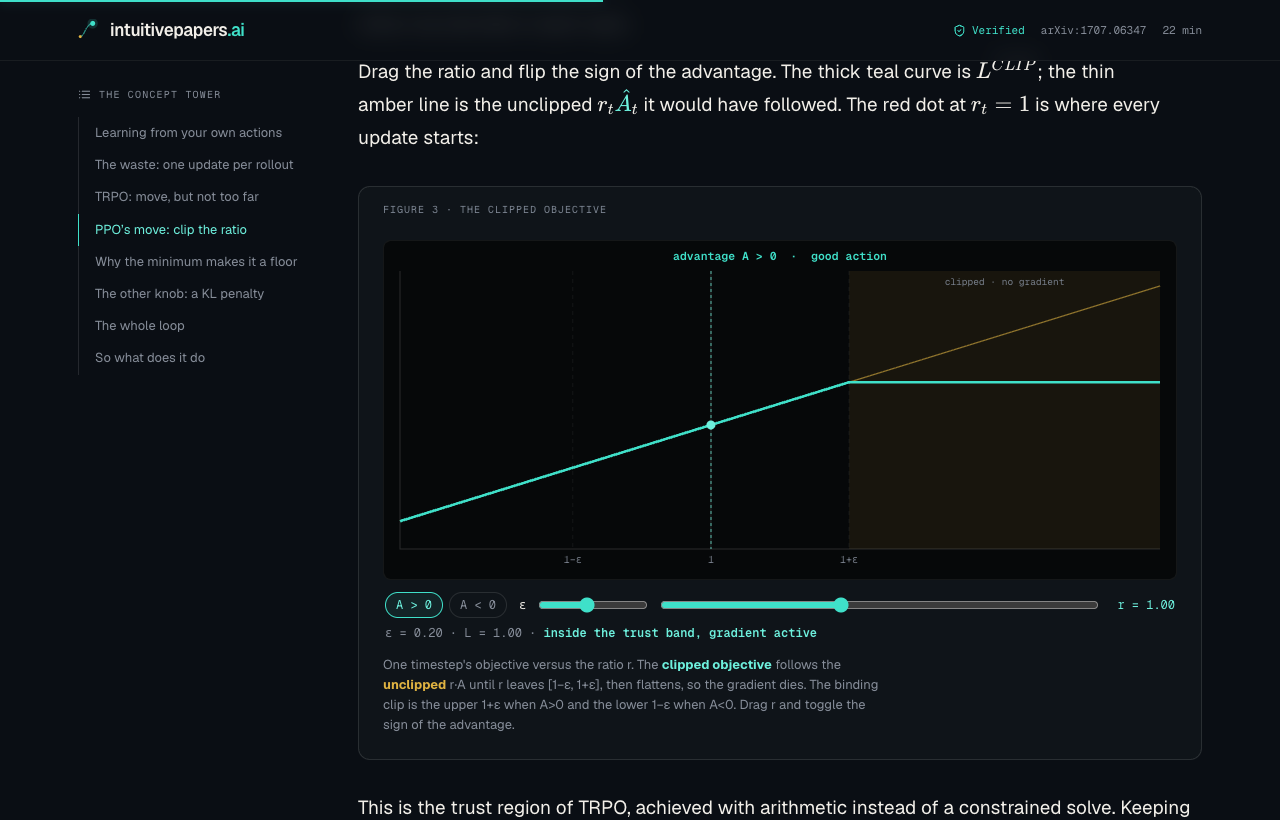
The clipped objective from PPO. Drag the ratio, flip the sign of the advantage, watch the gradient go to zero outside the trust band.

An explainer on a phone, the same figures inline.

Every image scored against every caption. The bright diagonal is the real pairs CLIP pulls together; everything off it gets pushed apart.
How the machine works
A single explain-this-paper call gives you the subtly wrong summary. The quality comes from a pipeline of separate steps that verify every claim against the paper, the primary literature, and the authors’ code, then hand the draft to a panel of adversarial critics before it ships. It runs on a timer on the Mac mini under my desk, mostly without a human in the loop, picking the next paper off a queue and deploying the result. A reader’s fix from the feedback form goes into that page and into the rules for the next one.
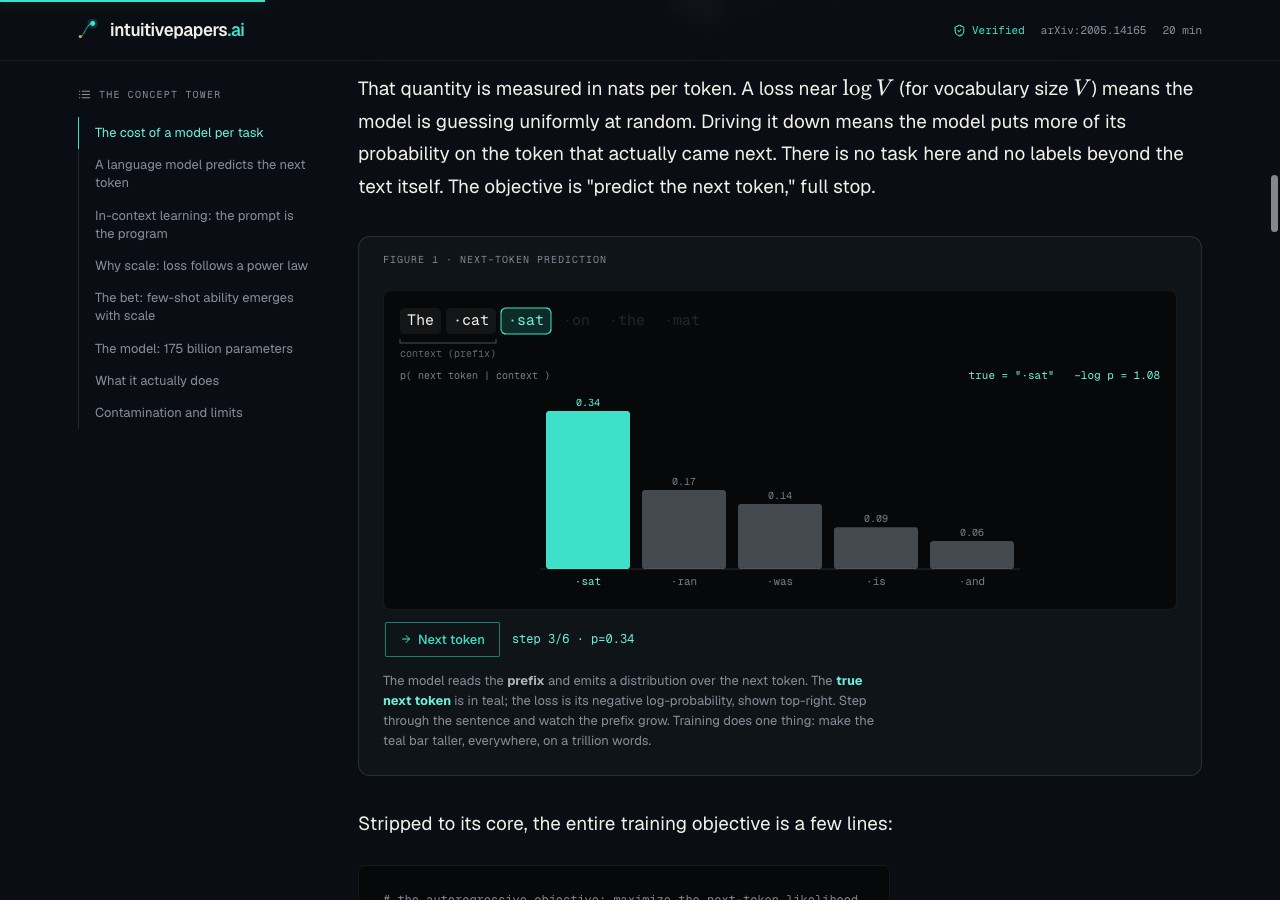
A Mamba block, broken down. There are well over a hundred custom figures across the library, all hand-drawn canvas, no charting library.
Where it’s going
The supply of papers is exploding and the supply of understanding isn’t, because understanding is bottlenecked on teaching time. A machine that does the patient, figure-by-figure work of a good teacher and checks every claim against the source moves that bottleneck.
If there’s a paper you’ve been meaning to understand, intuitivepapers.ai has a queue where you can request it or upvote someone else’s, and the machine works down the list. I built it for myself, mostly. If it saves someone else a few hours, even better.
