3D Reconstruction From Public Photos with Machine Learning
Can we reconstruct the world from public photos?
Mapping the World
The internet provides an abundance of public photos from various sources: Reddit, Youtube, Google Maps photo uploads, and so forth.
Public photos available on Google Maps
I wondered: is it possible to create a 3D map of the world from all this data? Cameras remove all the 3D information when the photo is taken - but using state of the art machine learning, we can bring it back, and turn a photo like this:

Public Safeway input image 0.
Into a 3D model like this:
Another example, from the famous Singapore Airport:

Public SG Airport input image.
And even an image of a forest:

Public Forest input image.
To achieve this, I used an ML depth model and some linear algebra.
Camera Projection
We can consider a camera as performing a projection from 3D to 2D, as in the image below. This removes information about the 3rd dimension: depth.
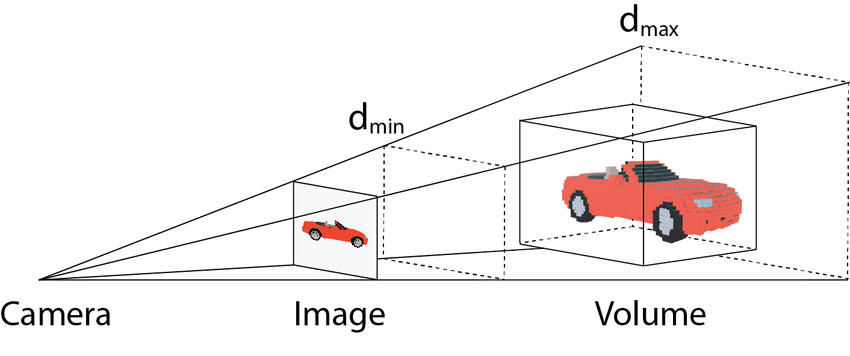
Camera projection from 3D to 2D. Source: [1]
Our task is to recover this 3rd dimension, and then figure out how to undo this projection.
Camera Intrinsics
It is not sufficient to know the depth for every pixel in the image to reconstruct it in 3D. This is because the properties of the camera - most importantly the focal length - determine how points in 3D get mapped to pixels in 2D, and so to undo this mapping, we need to have these properties of the camera. Consider the demonstration of this below, where different focal lengths produce significantly different images:

A demonstration of the effect of focal length on image. Source: [2]
Logically it follows that if we want to reconstruct the face in 3D from any of these images, we need to know the camera properties.
Using properties of similar triangles shown below, it can be seen that the relation between the image points and the 3D points are simple:
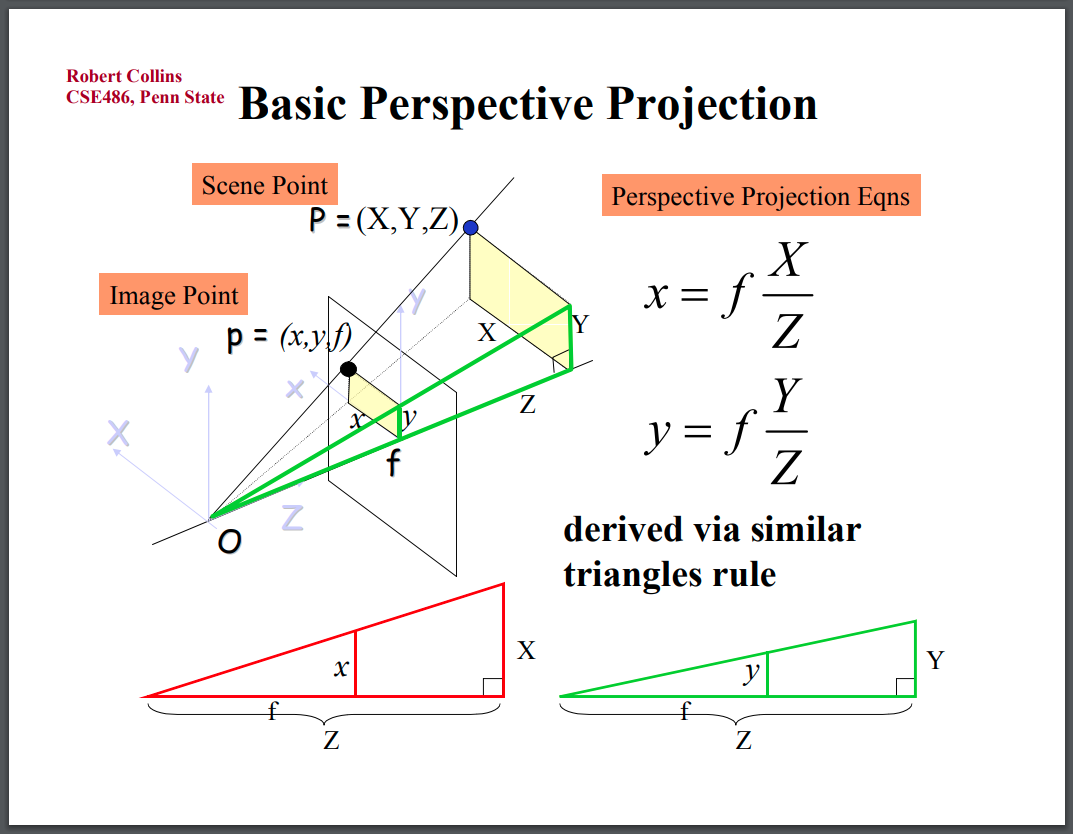
Camera Perspective Projection
Reversing this transformation to map image points back to 3D, we find:
So, the two missing pieces we need are the depth at each pixel, \(Z\), and the focal length of the camera, \(f\). Neither of these are immediately available from public photos. The EXIF data, which may have camera information, is typically removed.
Note, it’s also possible to describe the full transformation between 3D and 2D coordinate frames, taking into account the camera’s pose, shown below. But for the purpose of this article, we just consider the camera’s local coordinate frame.
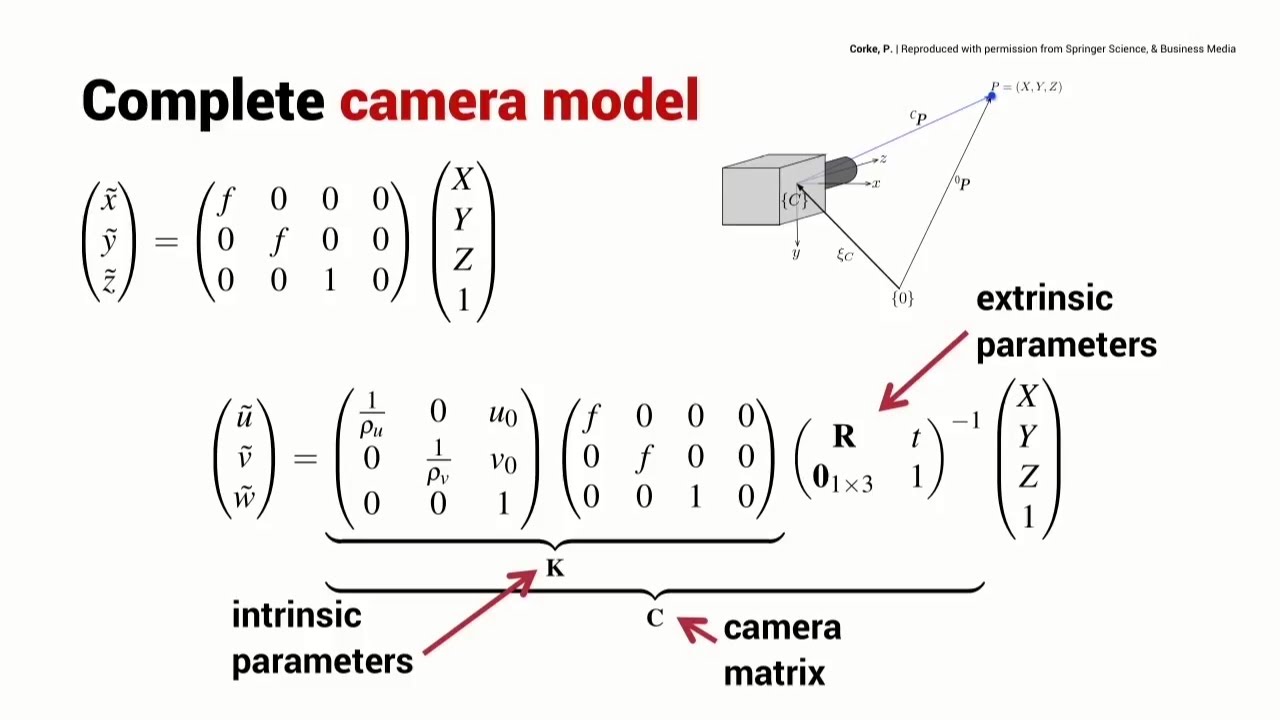
Complete Camera Model. Source: [3]
Depth Masks
Apple’s recently released DepthPro model made this project possible. While depth models have existed for a long time, I noticed this model was different in two ways: 1. It provided depth in an absolute, metric scale, which meant 3D reconstructions would actually have metric proportions, even when generated from a single mono image 2. It estimated the focal length of the camera for me

Depth Pro Teaser. Source: [4]
I ran this model on a bunch of public photos, estimating the depth masks and focal lengths, as shown below. For example, for this image:
Public Safeway input image 1.
The corresponding estimated depth mask and focal length are:

Safeway depth mask 1 and focal length predicted by the DepthPro model.
I then used equations \((2)\) to map each pixel back into 3D, created a point cloud, and then visualized it with Open3D:
3D Reconstruction
Check out all my examples, below. Notably, check out the NYC skyline example. I was curious to see how well it would work on a huge scene, like the skyline of NYC. As expected, the depth pro model did not produce a good depth mask. The training dataset almost certainly focused on smaller scales.
COEX Mall

Public COEX Mall input image.

COEX Mall depth mask and focal length predicted by the DepthPro model.
Forest
Public Forest input image.

Forest depth mask and focal length predicted by the DepthPro model.
NYC Skyline

Public NYC input image.
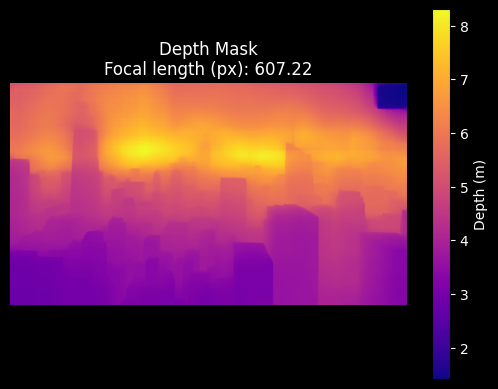
NYC depth mask and focal length predicted by the DepthPro model.
Safeway 1

Public Safeway input image 0.
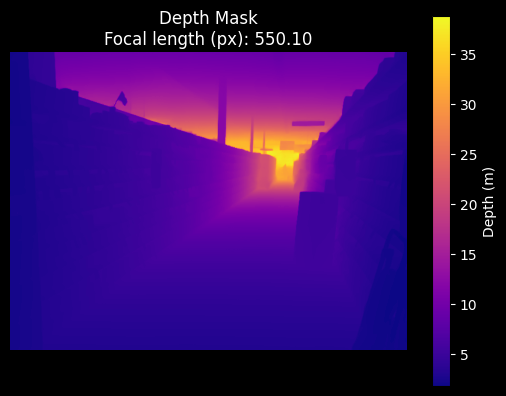
Safeway depth mask 0 and focal length predicted by the DepthPro model.
Safeway 2
Public Safeway input image 1.
Safeway depth mask 1 and focal length predicted by the DepthPro model.
Singapore Airport
Public SG Airport input image.
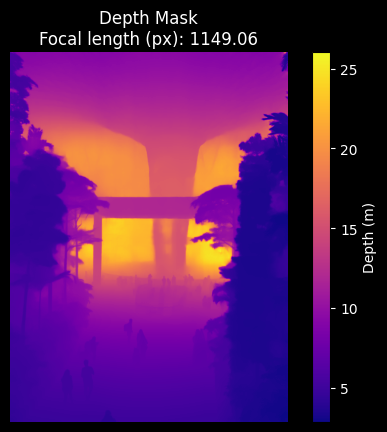
SG Airport depth mask and focal length predicted by the DepthPro model.
Footnotes
- Camera projection from 3D to 2D. Source: ResearchGate
- A demonstration of the effect of focal length on image. Source: DIY Photography
- Complete Camera Model. Source: Robot Academy
- Depth Pro Teaser. Source: Apple
